NVIDIA NeMo फ्रेमवर्क

विशेष विवरण
- प्रोडक्ट का नाम: NVIDIA NeMo फ्रेमवर्क
- प्रभावित प्लेटफार्म: विंडोज़, लिनक्स, मैकओएस
- प्रभावित संस्करण: 24 से पहले के सभी संस्करण
- सुरक्षा भेद्यता: सीवीई-2025-23360
- जोखिम मूल्यांकन आधार स्कोर: 7.1 (सीवीएसएस v3.1)
उत्पाद उपयोग निर्देश
सुरक्षा अद्यतन स्थापना:
अपने सिस्टम की सुरक्षा के लिए, इन चरणों का पालन करें:
- GitHub पर NeMo-Framework-Launcher Releases पृष्ठ से नवीनतम रिलीज़ डाउनलोड करें।
- अधिक जानकारी के लिए NVIDIA Product Security पर जाएं।
सुरक्षा अद्यतन विवरण:
सुरक्षा अद्यतन NVIDIA NeMo फ्रेमवर्क में एक भेद्यता को संबोधित करता है जो कोड निष्पादन और डेटा हानि का कारण बन सकता हैampering।
सॉफ्टवेयर अपग्रेड:
यदि आप पहले वाली शाखा रिलीज़ का उपयोग कर रहे हैं, तो सुरक्षा समस्या को हल करने के लिए नवीनतम शाखा रिलीज़ में अपग्रेड करने की अनुशंसा की जाती है।
ऊपरview
NVIDIA NeMo फ्रेमवर्क एक स्केलेबल और क्लाउड-नेटिव जेनरेटिव AI फ्रेमवर्क है जो शोधकर्ताओं और डेवलपर्स के लिए बनाया गया है बड़े भाषा मॉडल, मल्टीमॉडल, और भाषण ए.आई. (उदाहरण स्वचालित वाक् पहचान और भाषण के पाठ) यह उपयोगकर्ताओं को मौजूदा कोड और पूर्व-प्रशिक्षित मॉडल चेकपॉइंट्स का लाभ उठाकर नए जनरेटिव एआई मॉडल को कुशलतापूर्वक बनाने, अनुकूलित करने और तैनात करने में सक्षम बनाता है।
सेटअप निर्देश: NeMo फ्रेमवर्क स्थापित करें
NeMo Framework बड़े भाषा मॉडल (LLM) और मल्टीमॉडल मॉडल (MM) विकसित करने के लिए एंड-टू-एंड समर्थन प्रदान करता है। यह ऑन-प्रिमाइसेस, डेटा-सेंटर में या आपके पसंदीदा क्लाउड प्रदाता के साथ उपयोग करने की सुविधा प्रदान करता है। यह SLURM या Kubernetes सक्षम वातावरण पर निष्पादन का भी समर्थन करता है।

डेटा क्यूरेशन
निमो क्यूरेटर [1] एक पायथन लाइब्रेरी है जिसमें डेटा माइनिंग और सिंथेटिक डेटा जेनरेशन के लिए मॉड्यूल का एक सूट शामिल है। वे GPU के लिए स्केलेबल और अनुकूलित हैं, जो उन्हें LLM को प्रशिक्षित या फाइन-ट्यून करने के लिए प्राकृतिक भाषा डेटा को क्यूरेट करने के लिए आदर्श बनाता है। NeMo क्यूरेटर के साथ, आप व्यापक रॉ से उच्च-गुणवत्ता वाला टेक्स्ट कुशलतापूर्वक निकाल सकते हैं web डेटा स्रोत।
प्रशिक्षण और अनुकूलन
NeMo फ्रेमवर्क कुशल प्रशिक्षण और अनुकूलन के लिए उपकरण प्रदान करता है एलएलएम और मल्टीमॉडल मॉडल। इसमें कंप्यूट क्लस्टर सेटअप, डेटा डाउनलोडिंग और मॉडल हाइपरपैरामीटर के लिए डिफ़ॉल्ट कॉन्फ़िगरेशन शामिल हैं, जिन्हें नए डेटासेट और मॉडल पर प्रशिक्षित करने के लिए समायोजित किया जा सकता है। प्री-ट्रेनिंग के अलावा, NeMo सुपरवाइज्ड फ़ाइन-ट्यूनिंग (SFT) और पैरामीटर एफ़िशिएंट फ़ाइन-ट्यूनिंग (PEFT) तकनीकों जैसे LoRA, Ptuning और बहुत कुछ का समर्थन करता है।
NeMo में प्रशिक्षण शुरू करने के लिए दो विकल्प उपलब्ध हैं - NeMo 2.0 API इंटरफ़ेस का उपयोग करना या NeMo Run के साथ।
- निमो रन के साथ (अनुशंसित): NeMo Run विभिन्न कंप्यूट वातावरणों में प्रयोगों के कॉन्फ़िगरेशन, निष्पादन और प्रबंधन को सुव्यवस्थित करने के लिए एक इंटरफ़ेस प्रदान करता है। इसमें आपके वर्कस्टेशन पर स्थानीय रूप से या बड़े क्लस्टर पर जॉब लॉन्च करना शामिल है - दोनों SLURM सक्षम या क्लाउड वातावरण में Kubernetes।
- NeMo Run के साथ प्री-ट्रेनिंग और PEFT क्विकस्टार्ट
- NeMo 2.0 API का उपयोग करना: यह विधि छोटे मॉडल से जुड़े सरल सेटअप के साथ अच्छी तरह से काम करती है, या यदि आप अपना खुद का कस्टम डेटालोडर, ट्रेनिंग लूप या मॉडल लेयर बदलने में रुचि रखते हैं। यह आपको कॉन्फ़िगरेशन पर अधिक लचीलापन और नियंत्रण देता है, और प्रोग्रामेटिक रूप से कॉन्फ़िगरेशन को विस्तारित और अनुकूलित करना आसान बनाता है।
-
ट्राNeMo 2.0 API के साथ क्विकस्टार्ट प्रारंभ करना
-
NeMo 1.0 से NeMo 2.0 API पर माइग्रेट करना
-
संरेखण
- निमो-एलाइनर [1] कुशल मॉडल संरेखण के लिए एक स्केलेबल टूलकिट है। टूलकिट में स्टीयरएलएम, डीपीओ, मानव फीडबैक से सुदृढीकरण सीखना (आरएलएचएफ), और बहुत कुछ जैसे अत्याधुनिक मॉडल संरेखण एल्गोरिदम के लिए समर्थन है। ये एल्गोरिदम उपयोगकर्ताओं को भाषा मॉडल को अधिक सुरक्षित, हानिरहित और सहायक बनाने के लिए संरेखित करने में सक्षम बनाते हैं।
- सभी NeMo-Aligner चेकपॉइंट NeMo पारिस्थितिकी तंत्र के साथ क्रॉस-संगत हैं, जिससे आगे अनुकूलन और अनुमान परिनियोजन की अनुमति मिलती है।
छोटे GPT-2B मॉडल पर RLHF के सभी तीन चरणों का चरण-दर-चरण वर्कफ़्लो:
- एसएफटी प्रशिक्षण
- पुरस्कार मॉडल प्रशिक्षण
- पीपीओ प्रशिक्षण
इसके अतिरिक्त, हम विभिन्न अन्य नवीन संरेखण विधियों के लिए समर्थन प्रदर्शित करते हैं:
- डीपीओ: आरएलएचएफ की तुलना में एक हल्का संरेखण एल्गोरिथ्म जिसमें सरल हानि फ़ंक्शन है।
- स्व-प्ले फाइन-ट्यूनिंग (एसपीआईएन)
- स्टीयरएलएम: कंडीशन्ड-एसएफटी पर आधारित एक तकनीक, जिसमें स्टीयरेबल आउटपुट होता है।
अधिक जानकारी के लिए दस्तावेज़ देखें: संरेखण दस्तावेज़ीकरण
मल्टीमॉडल मॉडल
- NeMo फ्रेमवर्क कई श्रेणियों में अत्याधुनिक मल्टीमॉडल मॉडलों को प्रशिक्षित और तैनात करने के लिए अनुकूलित सॉफ्टवेयर प्रदान करता है: मल्टीमॉडल भाषा मॉडल, विज़न-लैंग्वेज फाउंडेशन, टेक्स्ट-टू-इमेज मॉडल, और न्यूरल रेडिएंस फील्ड्स (NeRF) का उपयोग करके 2D जेनरेशन से परे।
- प्रत्येक श्रेणी को क्षेत्र की विशिष्ट आवश्यकताओं और प्रगति को पूरा करने के लिए डिज़ाइन किया गया है, जिसमें पाठ, चित्र और 3D मॉडल सहित डेटा प्रकारों की एक विस्तृत श्रृंखला को संभालने के लिए अत्याधुनिक मॉडल का लाभ उठाया गया है।
टिप्पणी
हम मल्टीमॉडल मॉडल के लिए समर्थन को NeMo 1.0 से NeMo 2.0 में माइग्रेट कर रहे हैं। यदि आप इस बीच इस डोमेन को एक्सप्लोर करना चाहते हैं, तो कृपया NeMo 24.07 (पिछला) रिलीज़ के लिए दस्तावेज़ देखें।
परिनियोजन और अनुमान
NeMo फ्रेमवर्क LLM अनुमान के लिए विभिन्न पथ प्रदान करता है, जो विभिन्न परिनियोजन परिदृश्यों और प्रदर्शन आवश्यकताओं को पूरा करता है।
NVIDIA NIM के साथ परिनियोजित करें
- NeMo फ्रेमवर्क NVIDIA NIM के माध्यम से एंटरप्राइज़-स्तरीय मॉडल परिनियोजन टूल के साथ सहजता से एकीकृत होता है। यह एकीकरण NVIDIA TensorRT-LLM द्वारा संचालित है, जो अनुकूलित और स्केलेबल अनुमान सुनिश्चित करता है।
- NIM पर अधिक जानकारी के लिए NVIDIA वेबसाइट पर जाएं webसाइट।
TensorRT-LLM या vLLM के साथ परिनियोजित करें
- NeMo फ्रेमवर्क दो अनुमान अनुकूलित लाइब्रेरीज़, TensorRT-LLM और vLLM में मॉडल्स को निर्यात करने, तथा NVIDIA Triton Inference Server के साथ निर्यातित मॉडल को तैनात करने के लिए स्क्रिप्ट और API प्रदान करता है।
- अनुकूलित प्रदर्शन की आवश्यकता वाले परिदृश्यों के लिए, NeMo मॉडल TensorRT-LLM का लाभ उठा सकते हैं, जो NVIDIA GPU पर LLM अनुमान को तेज करने और अनुकूलित करने के लिए एक विशेष लाइब्रेरी है। इस प्रक्रिया में nemo.export मॉड्यूल का उपयोग करके NeMo मॉडल को TensorRT-LLM के साथ संगत प्रारूप में परिवर्तित करना शामिल है।
- एलएलएम की तैनाती समाप्तview
- NIM के साथ NeMo लार्ज लैंग्वेज मॉडल तैनात करें
- TensorRT-LLM के साथ NeMo लार्ज लैंग्वेज मॉडल तैनात करें
- vLLM के साथ NeMo बड़े भाषा मॉडल तैनात करें
समर्थित मॉडल
बड़े भाषा मॉडल
| बड़े भाषा मॉडल | प्रीट्रेनिंग और एसएफटी | पीईएफटी | संरेखण | एफपी8 प्रशिक्षण अभिसरण | टीआरटी/टीआरटीएलएलएम | गले लगाने वाले चेहरे से और उसमें परिवर्तित करें | मूल्यांकन |
|---|---|---|---|---|---|---|---|
| लामा3 8बी/70बी, लामा3.1 405बी | हाँ | हाँ | x | हाँ (आंशिक रूप से सत्यापित) | हाँ | दोनों | हाँ |
| मिक्सट्रल 8x7B/8x22B | हाँ | हाँ | x | हां (असत्यापित) | हाँ | दोनों | हाँ |
| नेमोट्रॉन 3 8बी | हाँ | x | x | हां (असत्यापित) | x | दोनों | हाँ |
| नेमोट्रॉन 4 340बी | हाँ | x | x | हां (असत्यापित) | x | दोनों | हाँ |
| बाइचुआन2 7बी | हाँ | हाँ | x | हां (असत्यापित) | x | दोनों | हाँ |
| चैटGLM3 6B | हाँ | हाँ | x | हां (असत्यापित) | x | दोनों | हाँ |
| जेम्मा 2बी/7बी | हाँ | हाँ | x | हां (असत्यापित) | हाँ | दोनों | हाँ |
| जेम्मा2 2बी/9बी/27बी | हाँ | हाँ | x | हां (असत्यापित) | x | दोनों | हाँ |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | हाँ | हाँ | x | हां (असत्यापित) | x | x | हाँ |
| फी3 मिनी 4k | x | हाँ | x | हां (असत्यापित) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | हाँ | हाँ | x | हां (असत्यापित) | हाँ | दोनों | हाँ |
| स्टारकोडर 15B | हाँ | हाँ | x | हां (असत्यापित) | हाँ | दोनों | हाँ |
| स्टारकोडर2 3बी/7बी/15बी | हाँ | हाँ | x | हां (असत्यापित) | हाँ | दोनों | हाँ |
| बर्ट 110एम/340एम | हाँ | हाँ | x | हां (असत्यापित) | x | दोनों | x |
| टी5 220एम/3बी/11बी | हाँ | हाँ | x | x | x | x | x |
दृष्टि भाषा मॉडल
| दृष्टि भाषा मॉडल | प्रीट्रेनिंग और एसएफटी | पीईएफटी | संरेखण | एफपी8 प्रशिक्षण अभिसरण | टीआरटी/टीआरटीएलएलएम | गले लगाने वाले चेहरे से और उसमें परिवर्तित करें | मूल्यांकन |
|---|---|---|---|---|---|---|---|
| नेवा (LLaVA 1.5) | हाँ | हाँ | x | हां (असत्यापित) | x | से | x |
| लामा 3.2 विज़न 11बी/90बी | हाँ | हाँ | x | हां (असत्यापित) | x | से | x |
| एलएलएवीए नेक्स्ट (एलएलएवीए 1.6) | हाँ | हाँ | x | हां (असत्यापित) | x | से | x |
मॉडल एम्बेड करना
| भाषा मॉडल एम्बेड करना | प्रीट्रेनिंग और एसएफटी | पीईएफटी | संरेखण | एफपी8 प्रशिक्षण अभिसरण | टीआरटी/टीआरटीएलएलएम | गले लगाने वाले चेहरे से और उसमें परिवर्तित करें | मूल्यांकन |
|---|---|---|---|---|---|---|---|
| एसबीईआरटी 340एम | हाँ | x | x | हां (असत्यापित) | x | दोनों | x |
| लामा 3.2 एम्बेडिंग 1बी | हाँ | x | x | हां (असत्यापित) | x | दोनों | x |
विश्व फाउंडेशन मॉडल
| विश्व फाउंडेशन मॉडल | प्रशिक्षण के बाद | त्वरित अनुमान |
|---|---|---|
| कॉस्मोस-1.0-डिफ्यूजन-टेक्स्ट2वर्ल्ड-7बी | हाँ | हाँ |
| कॉस्मोस-1.0-डिफ्यूजन-टेक्स्ट2वर्ल्ड-14बी | हाँ | हाँ |
| कॉस्मोस-1.0-डिफ्यूजन-वीडियो2वर्ल्ड-7बी | जल्द आ रहा है | जल्द आ रहा है |
| कॉस्मोस-1.0-डिफ्यूजन-वीडियो2वर्ल्ड-14बी | जल्द आ रहा है | जल्द आ रहा है |
| कॉस्मोस-1.0-ऑटोरिग्रैसिव-4B | हाँ | हाँ |
| कॉस्मोस-1.0-ऑटोरिग्रैसिव-वीडियो2वर्ल्ड-5बी | जल्द आ रहा है | जल्द आ रहा है |
| कॉस्मोस-1.0-ऑटोरिग्रैसिव-12B | हाँ | हाँ |
| कॉस्मोस-1.0-ऑटोरिग्रैसिव-वीडियो2वर्ल्ड-13बी | जल्द आ रहा है | जल्द आ रहा है |
टिप्पणी
NeMo प्रसार और ऑटोरिग्रैसिव आर्किटेक्चर दोनों के लिए प्रीट्रेनिंग का भी समर्थन करता है text2world आधार मॉडल.
भाषण ए.आई.
संवादात्मक AI मॉडल विकसित करना एक जटिल प्रक्रिया है जिसमें विशेष डोमेन के भीतर मॉडल को परिभाषित करना, निर्माण करना और प्रशिक्षण देना शामिल है। इस प्रक्रिया में आमतौर पर उच्च स्तर की सटीकता तक पहुँचने के लिए कई पुनरावृत्तियों की आवश्यकता होती है। इसमें अक्सर उच्च सटीकता प्राप्त करने, विभिन्न कार्यों और डोमेन-विशिष्ट डेटा पर फ़ाइन-ट्यूनिंग, प्रशिक्षण प्रदर्शन सुनिश्चित करने और अनुमान परिनियोजन के लिए मॉडल तैयार करने के लिए कई पुनरावृत्तियों की आवश्यकता होती है।
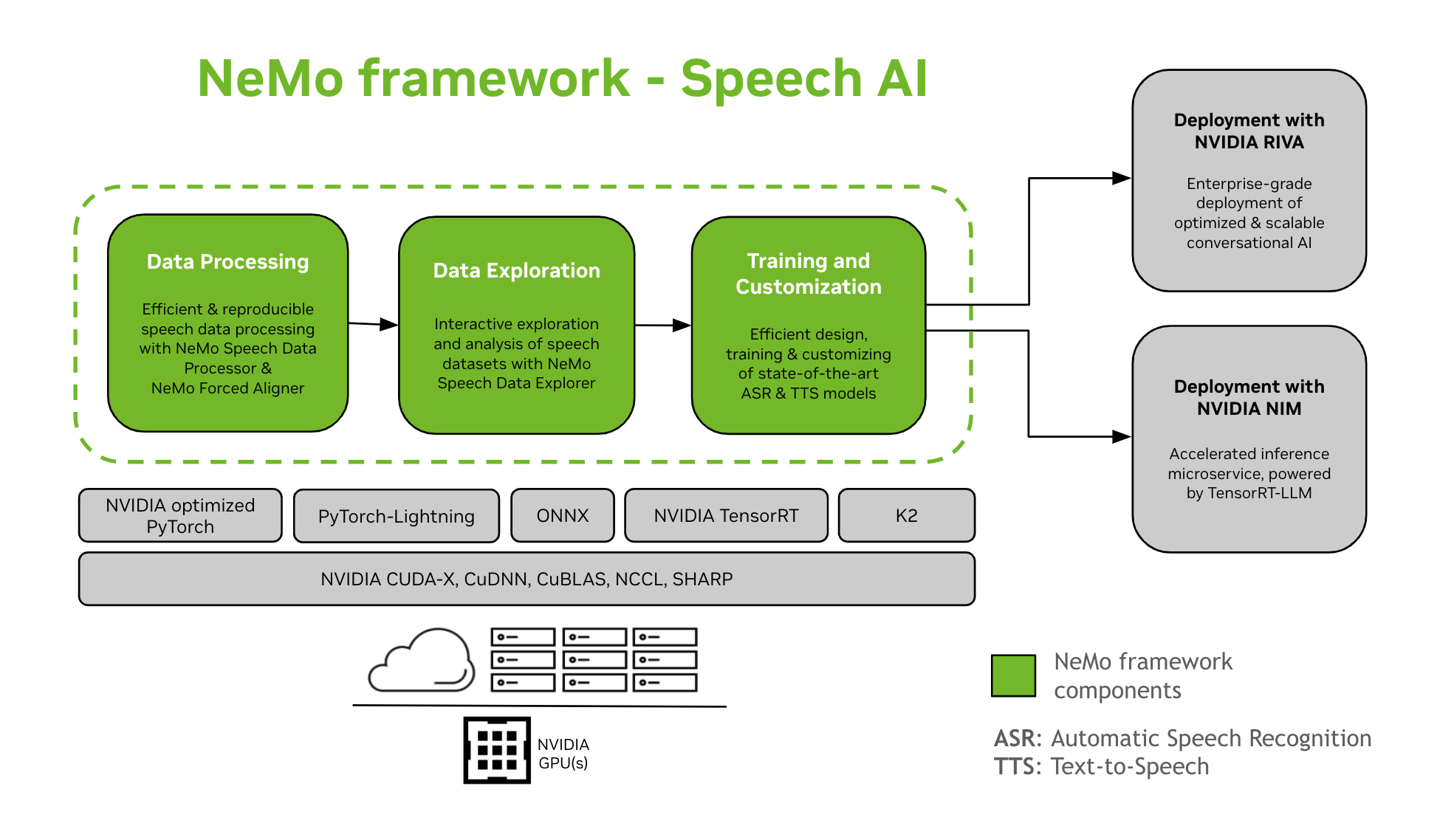
NeMo Framework स्पीच AI मॉडल के प्रशिक्षण और अनुकूलन के लिए सहायता प्रदान करता है। इसमें स्वचालित स्पीच पहचान (ASR) और टेक्स्ट-टू-स्पीच (TTS) संश्लेषण जैसे कार्य शामिल हैं। यह NVIDIA Riva के साथ एंटरप्राइज़-स्तरीय उत्पादन परिनियोजन के लिए एक सहज संक्रमण प्रदान करता है। डेवलपर्स और शोधकर्ताओं की सहायता के लिए, NeMo Framework में अत्याधुनिक पूर्व-प्रशिक्षित चेकपॉइंट, पुनरुत्पादनीय स्पीच डेटा प्रोसेसिंग के लिए उपकरण और स्पीच डेटासेट के इंटरैक्टिव अन्वेषण और विश्लेषण के लिए सुविधाएँ शामिल हैं। स्पीच AI के लिए NeMo Framework के घटक इस प्रकार हैं:
प्रशिक्षण और अनुकूलन
NeMo फ्रेमवर्क में स्पीच मॉडल को प्रशिक्षित और अनुकूलित करने के लिए आवश्यक सभी चीजें शामिल हैं (अस्र, भाषण वर्गीकरण, स्पीकर पहचान, स्पीकर डायरीकरण, और टीटीएस) को पुनरुत्पादनीय तरीके से प्रस्तुत किया गया है।
SOTA पूर्व प्रशिक्षित मॉडल
- NeMo फ्रेमवर्क कई प्रकार के अत्याधुनिक नुस्खे और पूर्व-प्रशिक्षित चेकपॉइंट प्रदान करता है अस्र और टीटीएस मॉडलों के साथ-साथ उन्हें लोड करने के निर्देश भी दिए गए हैं।
- भाषण उपकरण
- NeMo फ्रेमवर्क ASR और TTS मॉडल विकसित करने के लिए उपयोगी उपकरणों का एक सेट प्रदान करता है, जिसमें शामिल हैं:
- निमो फोर्स्ड एलाइनर (एनएफए) टोकन-, शब्द- और खंड-स्तरीय टाइमस्ट उत्पन्न करने के लिएampनेमो के सी.टी.सी.-आधारित स्वचालित स्पीच रिकॉग्निशन मॉडल का उपयोग करते हुए ऑडियो में स्पीच की पहचान करना।
- स्पीच डेटा प्रोसेसर (एसडीपी), भाषण डेटा प्रोसेसिंग को सरल बनाने के लिए एक टूलकिट। यह आपको कॉन्फ़िगरेशन में डेटा प्रोसेसिंग ऑपरेशन का प्रतिनिधित्व करने की अनुमति देता है file, बॉयलरप्लेट कोड को न्यूनतम करना और पुनरुत्पादन और साझाकरण की अनुमति देना।
- स्पीच डेटा एक्सप्लोरर (SDE), एक डैश-आधारित web भाषण डेटासेट के इंटरैक्टिव अन्वेषण और विश्लेषण के लिए अनुप्रयोग।
- डेटासेट निर्माण उपकरण जो लंबे ऑडियो को संरेखित करने की कार्यक्षमता प्रदान करता है fileसंबंधित प्रतिलेखों के साथ उन्हें छोटे टुकड़ों में विभाजित करें जो स्वचालित वाक् पहचान (एएसआर) मॉडल प्रशिक्षण के लिए उपयुक्त हैं।
- तुलना उपकरण एएसआर मॉडल के लिए शब्द सटीकता और उच्चारण स्तर पर विभिन्न एएसआर मॉडल की भविष्यवाणियों की तुलना करना।
- एएसआर मूल्यांकनकर्ता एएसआर मॉडल और वॉयस एक्टिविटी डिटेक्शन जैसी अन्य सुविधाओं के प्रदर्शन का मूल्यांकन करने के लिए।
- पाठ सामान्यीकरण उपकरण पाठ को लिखित रूप से बोले गए रूप में और इसके विपरीत रूपांतरित करने के लिए (उदाहरण के लिए "31वां" बनाम "इकतीसवां")।
- तैनाती का मार्ग
- NeMo फ्रेमवर्क का उपयोग करके प्रशिक्षित या अनुकूलित किए गए NeMo मॉडल को NVIDIA Riva के साथ अनुकूलित और तैनात किया जा सकता है। Riva विशेष रूप से पुश-बटन परिनियोजन के चरणों को स्वचालित करने के लिए डिज़ाइन किए गए कंटेनर और हेल्म चार्ट प्रदान करता है।
अन्य संसाधन
- निमो: NeMo फ्रेमवर्क के लिए मुख्य रिपोजिटरी
- निमो–दौड़ना: आपके मशीन लर्निंग प्रयोगों को कॉन्फ़िगर करने, लॉन्च करने और प्रबंधित करने के लिए एक उपकरण।
- निमो-अलाइनर: कुशल मॉडल संरेखण के लिए स्केलेबल टूलकिट
- निमो-क्यूरेटर: एलएलएम के लिए स्केलेबल डेटा प्री-प्रोसेसिंग और क्यूरेशन टूलकिट
निमो समुदाय के साथ जुड़ें, प्रश्न पूछें, सहायता प्राप्त करें या बग की रिपोर्ट करें।
- निमो चर्चाएँ
- निमो मुद्दे
प्रोग्रामिंग भाषाएं और फ्रेमवर्क
- पायथन: NeMo फ्रेमवर्क का उपयोग करने के लिए मुख्य इंटरफ़ेस
- पाइटॉर्च: NeMo फ्रेमवर्क PyTorch के शीर्ष पर बनाया गया है
लाइसेंस
- NeMo Github रेपो Apache 2.0 लाइसेंस के अंतर्गत लाइसेंस प्राप्त है
- NeMo Framework को NVIDIA AI PRODUCT AGREEMENT के तहत लाइसेंस प्राप्त है। कंटेनर को खींचकर और उसका उपयोग करके, आप इस लाइसेंस के नियमों और शर्तों को स्वीकार करते हैं।
- NeMo फ्रेमवर्क कंटेनर में मेटा लामा3 सामुदायिक लाइसेंस समझौते द्वारा शासित लामा सामग्रियां शामिल हैं।
फुटनोट
वर्तमान में, मल्टीमॉडल मॉडलों के लिए निमो क्यूरेटर और निमो एलाइनर समर्थन पर कार्य प्रगति पर है और यह बहुत जल्द उपलब्ध हो जाएगा।
सामान्य प्रश्न
प्रश्न: मैं कैसे जांच सकता हूं कि मेरा सिस्टम भेद्यता से प्रभावित है या नहीं?
उत्तर: आप यह जाँच सकते हैं कि आपका सिस्टम प्रभावित है या नहीं, इसके लिए आपको NVIDIA NeMo Framework के इंस्टॉल किए गए संस्करण की जाँच करनी होगी। यदि यह संस्करण 24 से कम है, तो आपका सिस्टम असुरक्षित हो सकता है।
प्रश्न: सुरक्षा समस्या CVE-2025-23360 की रिपोर्ट किसने की?
उत्तर: सुरक्षा समस्या की रिपोर्ट ऑर पेलेस - जेफ्रॉग सिक्योरिटी द्वारा की गई थी। NVIDIA उनके योगदान को स्वीकार करता है।
प्रश्न: मैं भविष्य में सुरक्षा बुलेटिन सूचनाएं कैसे प्राप्त कर सकता हूं?
उत्तर: सुरक्षा बुलेटिन सूचनाओं की सदस्यता लेने और उत्पाद सुरक्षा अपडेट के बारे में सूचित रहने के लिए NVIDIA उत्पाद सुरक्षा पृष्ठ पर जाएं।
दस्तावेज़ / संसाधन
 |
NVIDIA NeMo फ्रेमवर्क [पीडीएफ] उपयोगकर्ता गाइड NeMo फ्रेमवर्क, NeMo, फ्रेमवर्क |